









事例集
第16回:次世代トランジスタの量子輸送シミュレーションに関する研究@大阪大学サイバーメディアセンター
今日のコンピューターを支える半導体チップは,多数のシリコンMOS型トランジスタを集積した回路から構成されています.MOS型トランジスタでは,比例縮小することにより,集積度の向上と同時に,高性能化を実現できます.このスケーリング則に従い,これまで,指数関数的にデバイスサイズが縮小されてきました.しかし,デバイスが極度に微細化された結果,スケーリング則による性能向上の限界が顕在化してきました.現在,この状況の打破を目指して,様々なデバイス構造・材料が提案されており,そのような次世代デバイスの性能を予測できるシミュレータの開発が急務となっています.このような背景のもと,「次世代トランジスタの量子輸送シミュレーションに関する研究」(H27年度,課題代表者:森伸也・大阪大学)では,新材料ナノワイヤトランジスタの性能予測に向けた,スーパーコンピューター支援による量子輸送デバイスシミュレータの開発を行っています.
本課題で扱うデバイスは,細いワイヤ形状のトランジスタです(図(a)).ゲート長が短くなると,従来の平面構造では,十分なゲート制御性が得られないため,ナノワイヤなどの立体構造にする必要があります.図(b)に,シリコンナノワイヤトランジスタにおける量子輸送シミュレーションの計算例を示します.極めて微細なデバイスでは,電子が量子力学に従って運動するという量子性を無視することができません.量子論に基づく輸送方程式は,従来の古典的な手法より,多くの計算資源が必要であり,スーパーコンピューター支援が必須です.
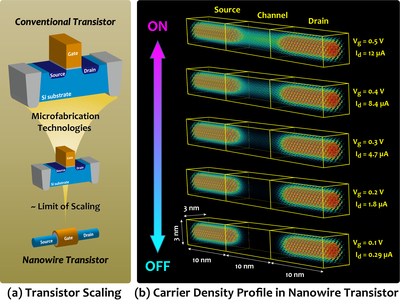
図(b)は,シリコンナノワイヤトランジスタにおいて散乱を無視した結果です.今後は,シリコン以外の新しい材料において,フォノンなどの散乱過程を考慮したシミュレータの実現を目指します.そのためには,新材料を柔軟に扱うことのできる第一原理計算との連携に加え,並列計算などの計算科学的手法の併用による高速化が課題です.この課題の解決に向けて,量子輸送理論・半導体デバイスモデリングを専門とする研究者に,計算科学・応用数学の専門家を加えたチームを構成して,共同研究を実施しています.
第15回:大規模計算結果の効果的な利用に向けた高精細可視化イメージ遠隔配信システムの実証@大阪大学サイバーメディアセンター
高性能計算システムを利用した大規模計算は、多くの研究分野において必要不可欠になっています。しかし、高性能計算システムは数が限られているため、今後はネットワークを介した遠隔利用がより一般的になることが予測されます。「大規模計算結果の効果的な利用に向けた高精細可視化イメージ遠隔配信システムの実証」(H27、課題代表者:阿部洋丈 ・筑波大学)では、遠隔地で実行された大規模計算結果の迅速かつ直感的な理解を可能とするための可視化イメージ配信システムの実証実験を行います。当システムは、計算機利用者側に設置された大型表示装置、とりわけタイルドディスプレイと呼ばれる大規模高精細可視化装置と、遠隔地の高性能システムを広域ネットワーク経由で相互に接続し、遠隔地で行われた大規模計算結果の可視化イメージを直接的にタイルドディスプレイに表示します。

本研究では、情報通信研究機構と大阪大学との共同研究プロジェクトにおいて開発した当該システムのプロトタイプ [1] を活用し、大学や研究拠点から構成される広域環境上での有用性を検証します。具体的に、新しいネットワーキンングのコンセプトSoftware Defined Networking(SDN)に基づいたネットワーク経路制御を行い、異なる解像度の可視化装置間でのコンテンツ共有するため、解像度変更装置へ画像ストリーミングを誘導し、動的に解像度変更を行います。一方、インフラ基盤としては広域テストベッドネットワークJGN-X/RISE [2] を活用し、本研究の参画拠点間を接続することで、実証実験環境を整えています。本システムの環境事例の一つとして、この環境では大阪大学と東北大学の可視化装置を結び、遠隔講義システムにおけるコンテンツ共有の実験的運用を行い、本年度、実際に社会人向けの講義にて使用しました(右図)。
今後は、上述した動的な解像度変更を行うコンテンツ共有の実証を行い、近い将来、国際共同研究コミュニティPRAGMA [3] の保有する国際的なテストベッドネットワークへの適用を考えています。国際共同研究コミュニティに積極的に貢献しつつ、広域にまたがる可視化コンテツ共有の実証を行う予定です。
第14回:流体・固体連成を考慮する防災計算力学@京都大学学術情報メディアセンター
防災インフラ整備がある程度進んだ我が国においても,近年大規模な自然災害が発生し,大きな社会問題となっています.本課題「流体・固体連成現象を考慮する防災計算力学」(H27年度,課題代表者:牛島省・京都大学)では,多様な自然災害に対して,実際に人的・物的被害が発生するレベルの時間・空間スケールの力学現象に着目し,災害発生のメカニズムを合理的に扱う解析手法を確立するとともに,スーパーコンピュータを活用することによって,従来困難であった詳細かつ正確な災害予測と評価を行うことを目指しています.
本課題で扱う具体的な自然災害としては,東日本大震災において発生した巨大な津波災害,極端気象と呼ばれる条件下で発生する台風・集中豪雨と土砂災害や,冬期の豪雪災害などを対象とします.これらの自然災害は,力学の基礎的な側面から見ると,流体と固体が相互に連成して発生する現象という性質をもっています.このため,本課題では,流体・固体連成現象に対して,なるべく経験則等を用いず,現象の素過程を再現できる数値モデルである,粒子法と多相場解析手法などを利用して,ある程度具体的な被害予測やその検証などを進める予定です.
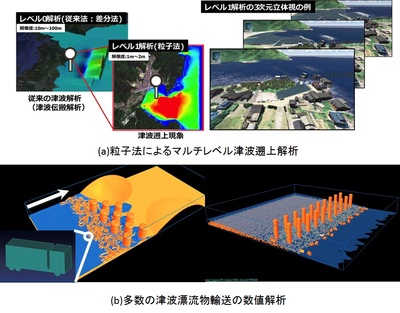 図(a)は,津波災害に対して,震源を含む大スケール領域から,被災を受ける比較的小スケール領域までを連続的に計算することを目的として,解析を2段階のスケールに分けるマルチレベル解析とその可視化例を示しています.この小スケール領域の計算では粒子法が使われています.また,図(b)は,津波および洪水氾濫流が発生した際に,船舶・車両・破壊された建築物の瓦礫など,非常に数多くの津波漂流物が自由表面流れにより輸送される状況を想定して,多相場解析手法を用いて漂流物の挙動を計算した例を示しています.実際に,氾濫流により生ずる浮遊物が構造物等に衝突すると,多大な人的・物的被害を引き起こすことが報告されています.そこで,本課題では,漂流物の衝突による建造物の破壊過程の計算モデルも合わせて開発する予定です.以上のように,本課題により,自然災害の被災規模の把握や,事前に災害対策を検討することが可能になると期待されます.
図(a)は,津波災害に対して,震源を含む大スケール領域から,被災を受ける比較的小スケール領域までを連続的に計算することを目的として,解析を2段階のスケールに分けるマルチレベル解析とその可視化例を示しています.この小スケール領域の計算では粒子法が使われています.また,図(b)は,津波および洪水氾濫流が発生した際に,船舶・車両・破壊された建築物の瓦礫など,非常に数多くの津波漂流物が自由表面流れにより輸送される状況を想定して,多相場解析手法を用いて漂流物の挙動を計算した例を示しています.実際に,氾濫流により生ずる浮遊物が構造物等に衝突すると,多大な人的・物的被害を引き起こすことが報告されています.そこで,本課題では,漂流物の衝突による建造物の破壊過程の計算モデルも合わせて開発する予定です.以上のように,本課題により,自然災害の被災規模の把握や,事前に災害対策を検討することが可能になると期待されます.
第13回:Xeon Phi・ベクトル計算機へのFDTDコードと電磁流体コードの最適化手法の研究@京都大学学術情報メディアセンター
近年のスーパーコンピュータシステム(スパコン)には、CPUだけで無く、何らかの加速器が組み込まれていることが一般的です。この加速器は、その名の通り演算性能が高く、大部分のスパコン演算性能を占めています。最近では、多くの演算コア(メニーコア)を持つXeon Phiという加速器が出てきており、使い方次第で、CPUで動作していたアプリケーションをそのままXeon Phiで動かすことができます。さらに次期Xeon Phiでは、完全にCPU無しで動作し、Xeon Phiだけで構成された計算機システムが登場します。一方で、Xeon Phi向けにアプリケーションを最適化しなければ、実行効率が極めて低く、Xeon Phiの性能は全く出ないことがわかっています。これからXeon Phiのようなメニーコアスパコンが出てくる中で、このシステムを活用できるアプリケーションの準備は非常に重要と考えられています。
一方で、最新のベクトル計算機であるSX-ACEの運用が2015年から始まっており、さらに次期ベクトル機の開発もすでに進められています。SX-ACEでは今までのベクトルCPUとは異なり、小さなベクトルチップからなる4ベクトルコア+スカラコアのCPUとなっています。一般的にベクトル計算機はメモリバンド幅が大きく、ステンシル計算が得意です。この特徴はXeon PhiやGPUと似ており、アプリケーション最適化の共通性もある可能性があります。
そこで「Xeon Phi・ベクトル計算機へのFDTDコードと電磁流体コードの最適化手法の研究」(H27、課題代表者:深沢圭一郎・京都大学)では、電磁場解析アプリケーションであるFDTDと電磁流体力学シミュレーションコードのMHDコードを利用して、Xeon PhiシステムとSX-ACEに向けた最適化を行い、その最適化手法をまとめることを目的としています。
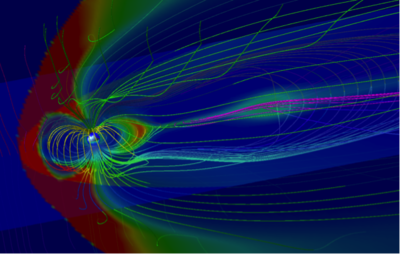
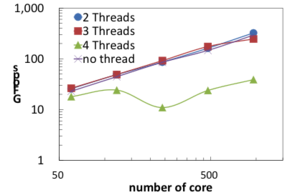
ここでは、MHDコードを利用した結果を紹介します。MHDコードでは右図 (地球磁気圏のMHDシミュレーション結果) のような地球周辺の広い領域で磁場構造(磁気圏)を計算し、地上に影響のある磁気嵐などの宇宙天気現象を再現しています。このMHDコードを京都大学のXeon Phiで評価したところ下図左 (Xeon Phi上でのMHDコードの性能) のようになり、コアあたりのスレッド数により大きく性能が変わることが分かりました。これは今までの計算機には無い特徴でした。また、東北大学SX-ACEでは、MHDコードを走らせると、単体のCPU性能は高くなりましたが 下図右(MHDコードの並列化性能) のように並列計算を行った際の性能維持率が悪くなっていました。ハードウェアの性能に依るところもありますが、低並列数で通信時間が顕著に出てしまうのは、最近の非ベクトル機には無い特徴であり、最適化が必要とわかりました。
今後は、Xeon PhiとSX-ACEでの最適化技術確立という研究目的を達成するために、今回顕在化した問題に対して、最適化を行っていき、成果を広く公開していく予定です。
第12回:次世代ペタスケールCFDのアルゴリズム研究@東北大学サイバーサイエンスセンター
近年,スーパーコンピュータを用いたシミュレーションに対する期待は,学術界のみならず産業界においてもますます大きくなりつつあり,サイエンスの発展に加えて革新的な製品開発のブレークスルーにつながることが期待されています.「次世代ペタスケールCFDのアルゴリズム研究」(H24-27、課題代表者:佐々木大輔・金沢工業大学)では,これまで計算機能力の限界により制限されていた様々な流体問題に挑戦し,数値流体(CFD: Computational Fluid Dynamics)シミュレーション技術の高度化を通じて航空機やガスタービン,自動車等様々な流体機械の効率的設計を目指しています.

現在の航空機設計では巡航性能のみならず,巡航時,離着陸時の環境負荷を十分に考慮する必要があります.特に,燃費の向上,窒素酸化物排出量の低減とともに,離着陸時の低騒音化が強く求められています.この問題に対して,エンジンや高揚力装置などの各騒音源を低騒音化する取り組みが精力的に行われていますが,本研究課題では航空機の形状自体を変更することによって大幅な低騒音化を目指しています.エンジンを主翼上面に取り付けるOver-the-Wing Nacelle (OWN)形状に着目し,右図(機体モデル表面と直下の瞬時圧力分布)に示すモデルを用いてBCM LEE(Linearized Euler Equation, LEE)に基づく騒音伝播解析ソルバにより騒音遮蔽効果を定量的に検証することに成功しました.5kHzまでのファン騒音の近傍場での伝播を解像するために,約7億点の格子点を用いて解析を行い,機体のナセル位置における騒音遮蔽量を周波数帯ごとに分解した結果,周波数帯により騒音の伝播特性が異なり,特に低周波数帯に対しての遮蔽効果は高周波数帯と比較してあまり大きくならないことを明らかにしています.
今後は, 本シミュレーションのさらなる大規模並列化,高度化に取り組み,環境に優しい航空機設計に貢献したいと考えています.
第11回:機械工学分野におけるシミュレーション科学の新展開@東北大学サイバーサイエンスセンター
「機械工学分野におけるシミュレーション科学の新展開」(H25,26年度、課題代表者:滝沢寛之・東北大学)では,スーパーコンピュータの利用分野の裾野の拡大を目指して,未だスーパーコンピュータの本格利用に至っていない先進的,かつ萌芽的機械工学分野のシミュレーションコードに着目し,これらの高速化に取り組みました.今回は,本研究課題で最適化を施した3つのシミュレーションコードのうち,ナノ粒子創製プロセスシミュレーションに関する例をご紹介します.
近年,ナノ粒子は新たな工業素材の創出に対する期待から高い注目を集めています.しかしながら,これらを可能とするには,高い機能性を有するナノ粒子を高速,かつ安価に製造する手法の開発が必要になります.本研究課題で取り扱うプラズマジェットを利用したナノ粒子創製では,材料蒸気から核生成・凝縮・凝集を経る相変化過程にあるナノ粒子の集団を対象にしています.このナノ粒子の集団が,1万℃を超えるプラズマと周囲の非電離気体の混合流動場において,移流-拡散輸送される非常に複雑な創製プロセスが必要になります.プラズマによるナノ粒子創製プロセス全体を包括する数値解析システムを構築できれば,ナノ粒子形成機構やプラズマ流の複雑熱流動場との干渉現象を解明できるのみならず,コンピュータ上で仮想的な実験を低コストで繰り返すことができるようになるため,工学的な意義は極めて大きいとされています.
今回のシミュレーションコードは,右図(プラズマジェットによる鉄ナノ粒子の集団形成と輸送プロセスの瞬間像:(a) 温度場, (b) 鉄蒸気濃度, (c) 鉄粒子濃度, (d) 平均粒子径)に示すように合金ナノ粒子集団成長過程の数理モデルと独自解法の構築に成功しています.サイバーサイエンスセンターでは同コードのベクトル化,並列化による性能チューニングを施すことで,約10.3倍の性能向上を達成しました.このように,サイバーサイエンスセンターは同コードの実用的な時間のシミュレーションの実現に大きく貢献しています.この機構解明は,今後のナノ粒子製造産業の発展の大きな足掛かりとなることが期待されています.このように本研究課題は,スーパーコンピュータを用いた機械工学分野におけるスーパーコンピュータの利用促進を加速しながら,数値シミュレーションの高度化・高性能化に貢献しています.
第10回:環オホーツク圏の海洋鉄循環シミュレーション@北海道大学情報基盤センター
オホーツク海とその周辺海域(環オホーツク圏)は、世界最大規模の基礎生産(海洋植物プランクトン増殖)で知られています。高い基礎生産は、食物連鎖を通して豊富な水産資源をもたらし、光合成等を通して地球温暖化等に関わる炭素循環 にも影響します。基礎生産が高いのは、環オホーツク圏では例外的に「鉄」が豊富なためです。すなわち、鉄は植物に必須 の元素ですが、海水には溶けにくいため不足しやすく、他の多くの海域で基礎生産を制限しています。そこで、「環オホーツク圏の海洋・大気シミュレーション」(H22〜27年度、課題代表者:中村知裕 ・北海道大学)では、環オホーツク圏の鉄循環の理解と予測に向けて、数値シミュレーションおよび用いる数値モデルの高速化チューニングを行いました。
海洋鉄循環は生物化学過程に伴う挙動と海水流動に伴う移流拡散からなります。前者は主要栄養塩をリンで代表させた 「鉄化学モデル」で表し、後者は海洋熱塩循環を良好に再現している「海洋大循環モデル」に鉄化学モデルを組み込んで計算しました。海洋への鉄の供給源は、主に黄砂などの風送塵および海底堆積物からの溶出・巻き上げです。これら供給源を 含め鉄化学モデルのパラメタ依存性も吟味しました。鉄化学モデル高速化のため、ノード内ハイブリッド並列化およびSMP 並列のチューニング(インライン展開と強制SMP並列化)を行い、並列化率は44%から94%に、実行時間は25%にと大幅に向上されました。
この鉄循環モデルを用いて気候学的季節変動のシミュレーションを行い、鉄とリン酸の濃度分布について観測されている 定性的特徴が再現できました。鉄濃度は、太平洋よりオホーツク海で高く、オホーツク海の中でも陸棚高密度水の経路であ る北岸から西岸にかけて高くなっています(右上図参照:溶存鉄濃度 中層)。鉛直断面では、北の陸棚上から南の中層へ高濃度域が伸びていま す(右下図参照:溶存鉄濃度 西岸沿い鉛直断面)。値も、観測から推測されている現実的範囲に収まっています。感度実験によると、オホーツク海陸棚上の 堆積物からの供給が鉄濃度に支配的影響を与えるのに対し、風送塵は広い範囲で海面鉄濃度を高めるものの影響は支配的で はありませんでした。加えて、限られた観測では分からなかった海洋混合層内の鉄収支についても新たな知見が得られました。
環オホーツク圏では、顕著な数年から数十年規模の変動に加えて、急速な温暖化が観測されています。海洋環境の変化は 海洋表層の栄養物質や基礎生産にも影響します。上記の成果はこうした変動の要因解明や予測の基盤となるでしょう。
第9回:放射線治療に関する計算機統計学的アプローチ@北海道大学情報基盤センター
ガンは、死因別死亡率のトップとなっており、社会的にも大きな関心が寄せられています。
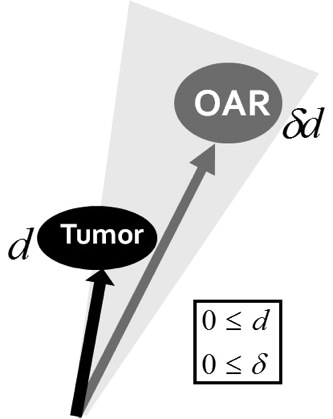
ガンに対する三大療法として,外科手術,化学療法,放射線治療があります。そのうち放射線治療は,患者への負担が小さいだけではなく,他の療法以上の治療成績を上げる場合もあります。放射線治療において,高線量を1回で照射するのではなく,低線量を複数回に分けて照射する分割照射放射線療法は,多くの場合,良好な治療成績を上げています。これは、国内外の放射線治療の多くの教科書には、「腫瘍と比べて正常組織は、低線量の放射線に対する損傷から回復する能力が高いためである」と書かれております。しかし,臨床的には,通常分割照射が好ましくない例も少なくありません。「放射線治療に関する計算機統計学的アプローチ」(H24〜25年度、課題代表者:水田正弘 ・北海道大学、課題番号12-DA02, 13-DA04)では、放射線医療関係者との共同研究により、計算機統計学の立場から、最適な照射計画について研究を推進しました。
腫瘍および正常組織に対する、放射線の影響の度合いを、線量の関数として表したものにLQモデルがあります。これは、1回線量をdGy(グレイ)とするとき、dの一次の影響と二次の影響を考えて、腫瘍および正常組織の生存率がexp(-αd-βd2)で表現するものです。dの値が小さいときや大きいときの当てはまりの改善や、腫瘍の再増殖の項を入れた拡張したモデルもありますが、この分野における基本的なモデルです。特に、α/βが重要な値とされています。研究代表者は、腫瘍におけるα/βと正常組織におけるα/βの比、つまり「比の比」の値と、副作用として正常組織へ照射される放射線の割合との大小関係により、分割照射放射線療法がよいかどうかを判断できることを見出し、放射線治療におけるトップジャーナルに掲載されました。本研究期間中に、拡張したLQモデルの場合の考察およびグラフィカル表現法について検討いたしました。研究期間後も、放射線治療計画において、腫瘍および、周りにある正常組織の状況に応じた、適切な照射回数、照射線量を医師に提示できるシステムの作成を目指しております。
第8回:TSUBAME-2.5を利用した大規模地震波伝播シミュレーション@東京工業大学学術国際情報センター
2011年3月11日に発生したマグニチュード9の東北地方太平洋沖地震は国内での観測史上最大の地震でした。そしてこの地震によって引き起こされた強い揺れと大きな津波によって、東日本地域を中心として計り知れないほどの被害がもたらされました。日本列島は海洋プレートが沈み込む地域にあたっていることから、この東北地方太平洋沖地震のようなプレートの沈み込みに伴う巨大地震が繰り返し発生しています。そのため、このような巨大地震の発生条件と、強い揺れや大きな津波が引き起こされる仕組みを探ることが重要な課題となっています。
「海溝型巨大地震を対象とした大規模並列地震波・津波伝播 シミュレーション」(H22〜27年度、課題代表者:竹中博士・岡山大学、課題番号10-NA03, 11-NA20, 12-NA12, 13-NA29, 14-NA25, 15-NA12)では、プロジェクトの一つとして、東京工業大学のクラスタ型GPUスーパーコンピューター「TSUBAME-2.5」を利用した大規模地震波シミュレーションによって、東北地方太平洋沖地震の「震源過程」、つまり断層の食い違い(すべり)が時空間的にどのように発生したかを研究しています。この研究では理論地震波波形が非常に重要な役割を果たします。すなわち、実際の地球は内部が3次元的な不均質構造になっており、地形・海水層などの細かな不規則性を持つ構造も含まれています。地震波はそのような構造によって経路が大きく歪められたり散乱を繰り返したりするため、地震波理論計算では、その効果を考慮することが決定的に重要になります。そのような計算には大規模で高速な計算能力が必要となることから、私たちはGPU(Graphics Processing Unit)の演算性能に着目し、地震波伝播シミュレーションを大規模並列GPU計算によって実行するためのプログラムの開発と応用を本課題を含めたサポートによって進めてきました。GPUは数千個以上の非常に多くの演算用コアを一つのプロセッサに内蔵しているため、極めて高い数値演算性能を発揮します。そのため私たちの研究目的を達成するうえで大きな力となっています。

図には、このようにして計算した東日本地域での地震波シミュレーションの一例を示します。これは2003年11月1日に発生したマグニチュード6.2の小規模地震による地震波伝播を計算して可視化したものです。海域では海底での地震動を海水を通して見ている図になっています。この結果はTSUBAME-2.5のGPU480基を同時に利用した大規模並列計算で得られたもので、不規則な地形などの影響で地震波が歪んだり散乱したりしながら伝播する様子が再現されています。このような小規模地震は震源自体の複雑性が比較的に少ないことから、地震波シミュレーションの正確さを確かめるうえで重要なデータとなります。私たちも、計算で得られた理論地震波波形がこの地震の観測波形の特徴を定量的によく再現することを確認しました。これは仮定した地球内部構造モデルやGPUを利用した計算方法が妥当なものであることを示します。一方で、地形や3次元不均質構造を含まない標準地球モデルで計算した理論波形は、この小地震の観測波形の特徴を再現できないこともわかりました。このことから、東北地方太平洋沖地震のような海域の巨大地震を調べるときには、3次元構造モデルにもとづいた地震波シミュレーションが欠かせないものであると言えます。私たちはこのようにしてTSUBAME-2.5を利用した大規模地震波シミュレーションによって得られた理論波形をもとにして、東北地方太平洋沖地震の破壊過程の解析を続け、この地震の特徴を明らかにしていこうと考えています。
第7回:GPUスパコンTSUBAME2.5によるマルチフェーズフィールド法の超大規模計算@東京工業大学学術国際情報センター
金属材料の強度や加工性の良さは、材料内部に存在するミクロンメートル(10のマイナス6乗メートル)程度の結晶粒や析出物(これらをミクロ組織と呼びます)のサイズや空間分布を変化することで、自在にコントロールすることができます。最近の金属材料研究の大きな技術課題は、金属材料の加工性を損なう事なく、強度を向上させることです。これにより、例えば自動車車体の軽量化や燃費向上に繋がると期待されています。しかし、金属材料内部のミクロ組織、特にその時間変化を直接観察することは困難であり、ミクロ組織の形成過程をより深く理解し、予測するための数値シミュレーション技術の確立が必要とされています。
「マルチフェーズフィールド法の大規模GPU計算による金属多結晶組織制御法の探索」(H25~H27年度, 課題代表者:山中晃徳・東京農工大学, 課題番号: jh130002-NA02, jh140033-NA18, jh150017-NA13)では、材料中で生じるミクロ組織形成を解析することのできる強力な数値シミュレーション法として注目されているマルチフェーズフィールド法の大規模GPU計算法を開発し、実験的方法では解析できないミクロ組織形成メカニズムやその制御方法を計算科学的観点から明らかにすることを目的としています。
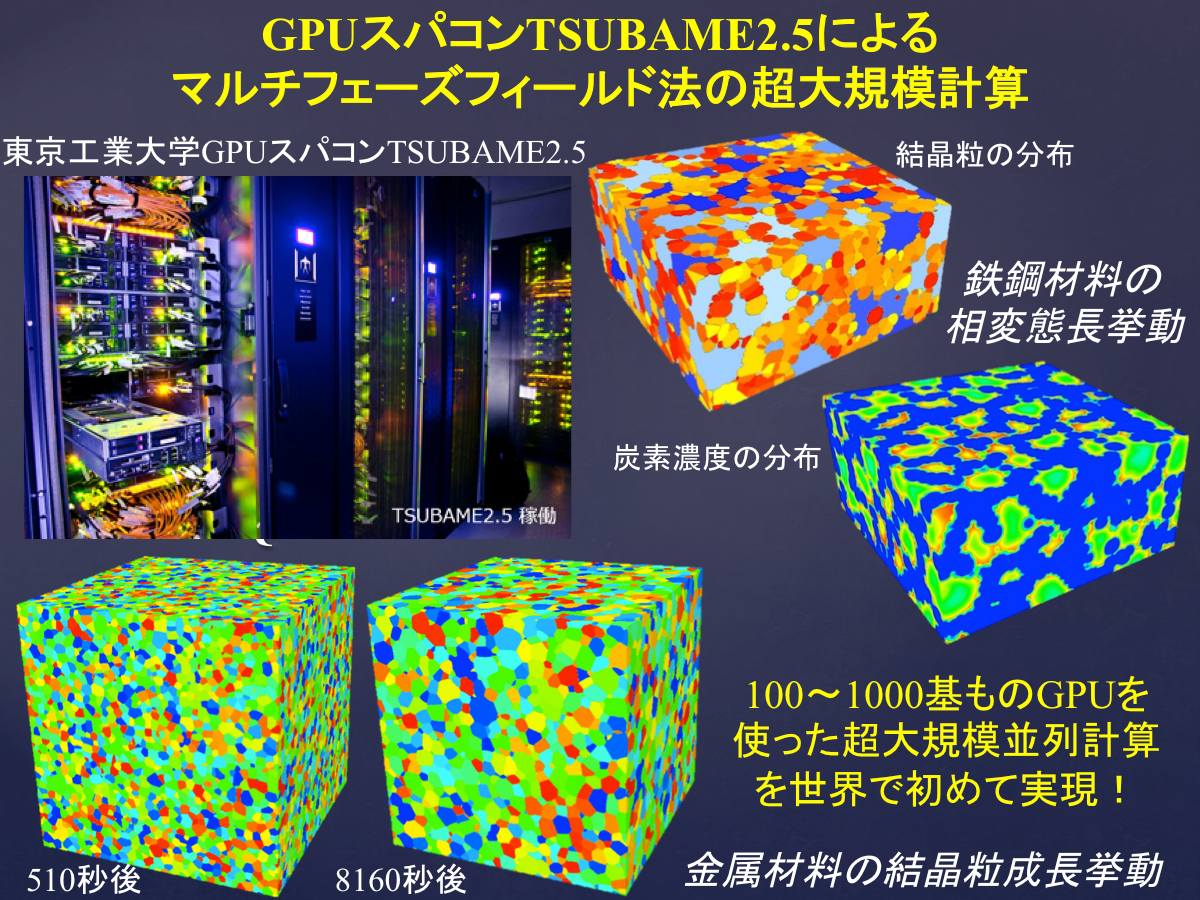
マルチフェーズフィールド法は、様々な材料におけるミクロ組織形成過程の数値シミュレーションに適用され、すでにその有用性は示されていますが、計算コストは大きく、材料学的に意味のある計算結果を得るために必要な3次元シミュレーションを行うためには高速な計算手法が必要とされています。そこで本研究では、東京工業大学学術国際情報センター(GSIC)の青木尊之教授、下川辺隆史助教と共同で、マルチフェーズフィールド法を多数のGPU(Graphics Processing Unit)で高速に計算するためのアルゴリズムの開発、プログラムコードの構築を行っています。さらに、構築したプログラムコードをGSICのスーパーコンピューターTSUBAME2.5に実装し、1000基ものGPUを使用した超大規模3次元シミュレーションが可能となりました。さらに、開発した並列計算アルゴリズムにより、高い並列化効果が得られたことも本研究の大きな成果となっています。
アメリカやヨーロッパでは、Integrated Computational Materials Engineeringと題して、計算材料科学を駆使した材料開発ツールの基盤構築が盛んに行われています。日本でも、データ駆動型材料開発システムの開発が進められており、本研究で開発したマルチフェーズフィールド法の大規模高速計算手法が活用され、最終的には産業界でも利用されることを目指しています。
第6回:超多自由度複雑流動現象解明のための計算科学@名古屋大学情報基盤センター

自然や工学において問題となる複雑流動現象の多くは実験や観測が困難な乱流であり、その特徴は,散逸性に比べ非線形性が強く、マルチスケール・マルチフィジックスで自由度数が巨大であることです。従来、これらの現象を解明するための糸口を見つけることが困難でした。しかし、10年で1000倍の著しい割合で高速化しているスーパーコンピュータを駆使した数値シミュレーションにより、解明できる可能性があると期待されています。
「超多自由度複雑流動現象解明のための計算科学」(H25~27年度, 課題代表者: 石原卓・名古屋大学, 課題番号: jh130029-NA17, jh140022-NA12, jh150020-NA14)では、流体方程式をモデル化せず高精度・高解像度に直接数値シミュレーションする方法(Direct Numerical Simulation: DNS)を用いて複雑流動現象を解明することを目的としています。具体的には、レイノルズ数(非線形性の強さを表すパラメータ)が高く、自由度数が巨大な乱流場を数値的に実現するための高効率な大規模DNS手法の開発、大規模なDNSで得られた乱流場を可視化・解析する技術の開発、また、これらの手法や技術を応用して複雑流動中の物理現象の解明に取り組んでいます。
本研究で開発した非圧縮性流体のDNS並列計算コードは「京」用に更に最適化・高速化され、乱流の世界最大規模DNS(格子点数122883)の実現に結びついています。また、本研究では「京」による大規模DNSで得られた大規模乱流データを可視化する手法も開発しています。これにより、非線形性が非常に強い、現実的な乱流場の詳細な観察が実現し、渦の組織構造の理解が進んでいます。一方、圧縮性乱流の一例として,自動車エンジン内で発生している多くの化学種と素反応を含む乱流燃焼のDNSの開発・実行と複雑な現象の解析方法開発を行うことにより、燃焼の物理の理解も進めています。さらに,乱流中の現象解明を深めるため,これらの乱流DNSの手法を基に,乱流中の微粒子の運動を効率的かつ精度よく追跡する方法の開発に成功しました。これにより、積乱雲中の雨滴や原始惑星系円盤中の微惑星の成長過程を解明するための大規模な数値実験が実現することが期待されています。
スーパーコンピュータや情報科学技術と流体物理の知識を駆使した、これらの計算科学的研究により、実験や観測が困難な超多自由度複雑流動現象を詳しく身近に観察・実験し、理解を深めることを可能とする要素技術の研究開発が進んでいます。
第5回:JHPCN-DFによる大規模データ系VR可視化解析の効率化@名古屋大学情報基盤センター
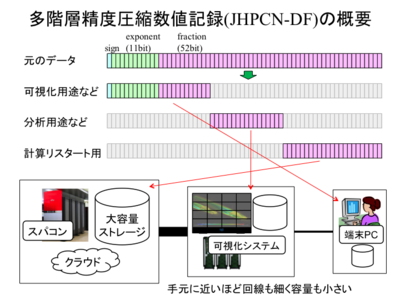
スパコン等を活用した大規模シミュレーションで生み出されるデータサイズは増加の一途を辿っています。これにより、スパコンでの計算結果を確認・可視化するために手元のパソコンへ転送する、という作業がシミュレーション・ワークフロー全体の律速(困り点)として顕在化しつつあります。スパコン上で計算と同時に可視化を行う解決方法もありますが、インタラクティブに視点やデータレンジを変更したり、可視化領域を変更したりするなどのVirtual Reality的な可視化解析のニーズは依然として高く、計算結果データは手元に必要とされています。よって、素早く効率的なデータ転送が望まれています。
「大規模データ系のVR可視化解析を効率化する多階層精度圧縮数値記録(JHPCN-DF)の実用化研究」(H26~27年度, 課題代表者: 萩田克美・防衛大学校, 課題番号: jh140004-NA02, jh150002-NA01)は、浮動小数点数のデータにおける上位ビットと下位ビットでの特性の違いに着目し、可視化や数値分析など用途ごとに必要な精度でデータをビット分割することで、多階層的に保存蓄積・データ転送する技術を研究開発しています。例えば可視化に上位ビットを必要とし、それで表現されるデータが高い圧縮率を期待できるため、結果として可視化用途に高速なデータ転送を可能とします。副次的効果として、アーカイブの長期化や割符的セキュリティなども期待されます。この手法は多階層精度圧縮数値記録(Jointed Hierarchical Precision Compression Number - Data Format; JHPCN-DF)と名付けられ、様々なシミュレーションにおける有効性検証、利便性向上や処理の高速化などが進められています。
また、名古屋大学情報基盤センターは、JHPCNの成果を広く普及させ、我が国の高性能計算技術をさらに高度化することを目的としてネットワーク型共同研究シンポジウムを開催しています。その第1回(平成27年1月20日)のメインテーマとしてJHPCN-DFを取り上げました。産学官の様々な研究者・技術者から同技術の幅広い活用例が報告され、さらに商用製品への積極的な活用展開やGitHubを通じたライブラリ配布による一般普及展開など、研究課題実施1年目から多様な発展をみせています。
将来、多くの大規模シミュレーションにおける利便性や効率の向上に資する要素技術となるとともに、アーカイブのストレージスペースの無駄排除(エコの実現)などに貢献することを目指し、研究開発が進められています。
第4回:精度保証付き多倍長並列演算環境の構築と計算機援用解析への展開@九州大学情報基盤研究開発センター
 「精度保証付き多倍長並列演算環境の構築と計算機援用解析への展開」(H22~23年度, 課題代表者: 山本 野人・電気通信大学, 課題番号: 10-NA01, 11-NA07)は、高速でメモリ効率が良く使いやすい精度保証付き多倍長並列演算ライブラリを作成し、数学的未解決問題に対する計算機援用証明への応用を目指すことを研究目的としています。 拠点共同研究は、山本 野人・松田 望(電気通信大学)、藤原 宏志(京都大学)、渡部 善 隆(九州大学)・木下 武彦(京都大学)の3グループで構成しました。
「精度保証付き多倍長並列演算環境の構築と計算機援用解析への展開」(H22~23年度, 課題代表者: 山本 野人・電気通信大学, 課題番号: 10-NA01, 11-NA07)は、高速でメモリ効率が良く使いやすい精度保証付き多倍長並列演算ライブラリを作成し、数学的未解決問題に対する計算機援用証明への応用を目指すことを研究目的としています。 拠点共同研究は、山本 野人・松田 望(電気通信大学)、藤原 宏志(京都大学)、渡部 善 隆(九州大学)・木下 武彦(京都大学)の3グループで構成しました。
山本・松田は、C++クラスライブラリを設計し、四則演算および平方根の実装と理論的評 価を与えました。また、乗算・除算の計算において区間半径拡大が起きない手法を提案す るとともに、多倍長演算において半径を低精度にすることによってメモリを節約すること が可能であり、下端・上端型と比較して区間演算のコストが改善されることを確認しまし た。さらに、C++で多倍長精度の精度保証付き区間演算を行うためのライブラリ LILIB[1] を公開しました。
藤原は、自身が開発した多倍長ライブラリ exflib の丸め制御技術を応用した区間演算の 実装に取り組み、Fortran インターフェースを開発しました。また,基本線形代数演算の 精度保証付き数値計算環境の構築を進め、あわせて丸め誤差の影響が深刻に現れる数値的に 不安定な問題に exflib の区間演算を適用し、丸め誤差の増大の定量的評価および必要な 計算桁数の見積が可能となることを示しました。
渡部・木下は、流体力学の安定性問題であ る Orr-Sommerfeld 方程式に対する解の包み込み定理を導き、解の存在検証および複素 固有値の除外では多倍長区間演算が必須となることを明らかにするとともに、定式化・アル ゴリズムの構築・多倍長区間による実装および精度保証に成功しました。
今後は、LILIB を用いて、丸め誤差の混入が顕著であるために解析が困難である応用問題 の精度保証に取り組む予定です。
第3回:負荷バランスや通信性能が予測困難な状況を想定した集団通信アルゴリズムの動的選択技術@九州大学情報基盤研究開発センター
 並列計算機をバッチ型で利用する場合、利用者から申請されたジョブがジョブスケジューラによって計算ノードに割り当てられます。特に、理化学研究所のRICC(RIKEN Integrated Clusterof Clusters)のメタスケジューラのように、出来るだけ空いている計算ノードが少なくなるように計算ノードの位置に関係なくプロセスを配置する場合、並列計算機全体のスループットは向上するものの、個々のジョブにおけるプログラム中の通信の性能は、そのジョブに割り当てられた計算ノードの相対的な位置関係によって大きく影響を受けてしまいます。並列プログラムにおける全プロセスによる総和の計算や全対全のコピー等の、集団通信と呼ばれる通信では、この転送性能の低下が大きな問題となります。そのため、実行時の状況に応じて適応的にアルゴリズムを選択する仕組みが必要となります。
並列計算機をバッチ型で利用する場合、利用者から申請されたジョブがジョブスケジューラによって計算ノードに割り当てられます。特に、理化学研究所のRICC(RIKEN Integrated Clusterof Clusters)のメタスケジューラのように、出来るだけ空いている計算ノードが少なくなるように計算ノードの位置に関係なくプロセスを配置する場合、並列計算機全体のスループットは向上するものの、個々のジョブにおけるプログラム中の通信の性能は、そのジョブに割り当てられた計算ノードの相対的な位置関係によって大きく影響を受けてしまいます。並列プログラムにおける全プロセスによる総和の計算や全対全のコピー等の、集団通信と呼ばれる通信では、この転送性能の低下が大きな問題となります。そのため、実行時の状況に応じて適応的にアルゴリズムを選択する仕組みが必要となります。
「負荷バランスや通信性能が予測困難な状況を想定した集団通信アルゴリズムの動的選択技術に関する研究」(H23年度,課題代表者:黒川原佳・理化学研究所)では、集団通信の実装アルゴリズムを実行中に試しながら、最適なものを選択する動的最適化技術を開発しました。この最適化技術は、プログラム中で繰り返し呼ばれる集団通信について、その最初のほうの繰り返し時に実装アルゴリズムを変えながら実行することにより、実行時の状況における各アルゴリズムの性能を取得し、その情報に基づいて最適なアルゴリズムを選択するものである。さらに、ランク配置を考慮した集団通信アルゴリズム性能予測技術を提案し、この技術を用いて遅いアルゴリズムを選択肢から排除する改良を加えました。これらの技術による効果を検証するために、PCクラスタ中の 32ノードを用いた Alltoall通信の所要時間を計測するプログラムで実験を行いました。このクラスタは出来るだけ空き少なくなるようにノードを割り当てるため、ジョブに割り当てられるノードの位置に規則性がありません。この環境による多様なノード配置に対して、提案手法が常に最速に近いアルゴリズムを選択できたこと、および、予めアルゴリズムを絞り込むことによってオーバヘッドを低減できたことを示しました。
第2回:BitVisorを活用した仮想計算機環境@東京大学情報基盤センター
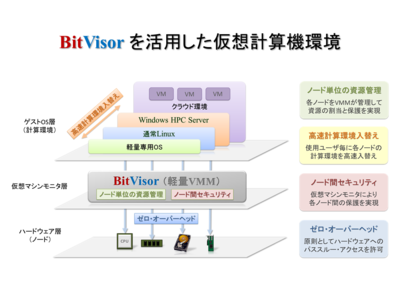 「次世代スーパーコンピューター向けの軽量な仮想計算機環境の実現に向けた研究開発」(H25,H27年度,課題代表者:品川高廣・東京大学)では、これまでに研究開発してきた軽量仮想マシンモニタ「BitVisor」を応用して、次世代スーパーコンピュータのための軽量な仮想計算環境の実現に向けた研究開発をおこないます。
「次世代スーパーコンピューター向けの軽量な仮想計算機環境の実現に向けた研究開発」(H25,H27年度,課題代表者:品川高廣・東京大学)では、これまでに研究開発してきた軽量仮想マシンモニタ「BitVisor」を応用して、次世代スーパーコンピュータのための軽量な仮想計算環境の実現に向けた研究開発をおこないます。
近年のスパコンは、多数のノードの集合体であり、これらのノードの性能を最大限に引き出すことが重要となっています。一方で、スパコンのユーザや用途は多様化しており、単一のシステムで全ての要望を満たすことは難しくなりつつあるのが現状です。しかし、ユーザがOSなどのシステムを自由に選択できるようにすると、ユーザ間でのセキュリティが問題となってきてしまいます。一般にOSは全てのハードウェア資源にアクセスすることができるため、他のユーザが利用するノードとの隔離や共有ストレージのセキュリティなどを確実に実施することが難しくなります。従って、システムとして確実なセキュリティを実現することが重要な課題となります。
本研究では、代表者が研究開発してきた仮想マシンモニタ「BitVisor」を応用して、OSに対するオーバーヘッドを極めて低く抑えつつ、必要最小限のセキュリティを確保することにより、多様な用途に応じたノード性能の最適化とセキュリティの確保を両立することを目指しています。一台のノードに複数の仮想マシンを構築するのではなく、ノードの集合の一部を切り出して仮想スパコンとしてユーザに割り当てることにより、それぞれのノードのハードウェアはユーザが直接制御できるようにします。これにより、目的・用途に応じたノードの最適化が可能になります。一方、セキュリティを実現するためには、仮想マシンモニタによって各ノードのハードウェアへのアクセスを必要最小限だけ監視してアクセス制御をおこなうようにします。それにより、性能とセキュリティの両立を実現しています。また本研究では、ノードの集合である仮想スパコンの管理機能や独自OSや大容量のデータを各ノードに高速にデプロイするための枠組みも提供することを目指しています。
第1回:高精度行列‐行列積アルゴリズムにおける並列化手法の開発@東京大学情報基盤センター
 「高精度行列‐行列積アルゴリズムにおける並列化手法の開発」(H23~24年度,課題代表者:片桐孝洋・東京大学)では、行列-行列積に代表される基本線形計算を集約した数値計算ライブラリBLAS (Basic Linear Algebra Subprograms)において、従来では演算速度は考慮しているが計算結果の正確性の考慮が不十分である問題を取り扱いました。この問題を解決する研究として、精度保証の研究が行われています。
「高精度行列‐行列積アルゴリズムにおける並列化手法の開発」(H23~24年度,課題代表者:片桐孝洋・東京大学)では、行列-行列積に代表される基本線形計算を集約した数値計算ライブラリBLAS (Basic Linear Algebra Subprograms)において、従来では演算速度は考慮しているが計算結果の正確性の考慮が不十分である問題を取り扱いました。この問題を解決する研究として、精度保証の研究が行われています。
精度保証アルゴリズムの研究は、早稲田大学の大石進一教授、東京女子大学の荻田武史准教授、芝浦工業大学の尾崎克久准教授のグループにおいて、世界に先駆けて研究されています。そこで本研究では、コンピュータ・サイエンス分野における高性能計算(HPC)を専門とする代表者と、数理科学を専門とする大石グループとの学際領域の共同研究により、精度保証を行った上で、スーパーコンピュータ環境を含む幅広い計算機環境で高性能となる実装方式の研究と数値計算ライブラリ開発を目指しています。
本研究では、BLASで利用できる高精度行列-行列積のアルゴリズムにおいて、演算効率の高い実装方式の開発に成功しました。高精度行列-行列計算アルゴリズムにおいては、演算が進むと、演算対象となる行列が零要素の多い「疎行列」になります。この疎行列の特性を利用した演算効率の高い実装方式を開発しました。疎行列を用いた演算において、疎行列-ベクトル積(Sparse Matrix-vector Multiplications、SpMV)を基本とした実装を行いました。高精度行列-行列積演算の特徴から、複数右辺を用いたSpMVを同時に行うことができます。この特性を利用し、CPU内にある高速メモリであるキャッシュを活用しデータアクセスの最適化を行うことができます。その結果、従来方式より約2.6倍の高速化が達成できました。
今後は、必要となるメモリ量の削減方式や、スーパーコンピュータを含む多種の計算機環境において高性能が達成できる技術「ソフトウェア自動チューニング」を適用した数値計算ライブラリの開発を推進し、多くの計算科学者が利用できる便利で高性能な数値計算ライブラリを提供できるように研究開発を進めていきます。